Rozdział 9 dplyr - część II
W tej części zapoznawania się z możliwościami pakietu dplyr dowiesz się jak w szybki sposób manipulować ramkami danych.
Ze względu na częste stosowanie rozwiazań z pakietów dplyr oraz tidyr najbardziej popularne rozwiązania zawarto w tzw. cheat-sheet’ie* * https://www.rstudio.com/wp-content/uploads/2015/02/data-wrangling-cheatsheet.pdf
Dane
Przed przystąpieniem do dalszej części pracy wczytaj do środowiska R godzinowe wartości pomiarów dla wybranych stacji meteorologicznych IMGW-PIB (2000-2015). Dane do ćwiczenia przygotowano w formacie RDS pod adresem: http://enwo.pl/przetwarzanie/dane/synop.rds. Nazwij wczytywany zbiór jako dane:
# Jeśli nie chcesz pobierać pliku na dysk możesz go wczytać bezpośrednio do R
# za pomocą poniższego kodu:
dane <- readRDS(gzcon(url("http://enwo.pl/przetwarzanie/dane/synop.rds")))
# ... Przyjrzyjmy się strukturze wczytanej bazy:
head(dane)## kod nazwa yy mm dd hh t2m ws wd slp tot_cl
## 1 352160330 POZ 2000 1 1 0 -1.1 3 250 1014.2 8
## 2 352160330 POZ 2000 1 1 1 -1.1 2 280 1014.2 8
## 3 352160330 POZ 2000 1 1 2 -1.1 2 250 1014.3 8
## 4 352160330 POZ 2000 1 1 3 -1.2 2 240 1014.3 8
## 5 352160330 POZ 2000 1 1 4 -1.2 2 200 1014.3 8
## 6 352160330 POZ 2000 1 1 5 -1.0 1 170 1014.3 8# oraz:
summary(dane)## kod nazwa yy mm
## Length:420766 Length:420766 Min. :2000 Min. : 1.000
## Class :character Class :character 1st Qu.:2004 1st Qu.: 4.000
## Mode :character Mode :character Median :2008 Median : 7.000
## Mean :2007 Mean : 6.523
## 3rd Qu.:2012 3rd Qu.:10.000
## Max. :2015 Max. :12.000
## dd hh t2m ws
## Min. : 1.00 Min. : 0.00 Min. :-30.10 Min. : 0.000
## 1st Qu.: 8.00 1st Qu.: 6.00 1st Qu.: 2.30 1st Qu.: 2.000
## Median :16.00 Median :12.00 Median : 9.20 Median : 3.000
## Mean :15.73 Mean :11.50 Mean : 9.16 Mean : 3.492
## 3rd Qu.:23.00 3rd Qu.:17.75 3rd Qu.: 15.90 3rd Qu.: 5.000
## Max. :31.00 Max. :23.00 Max. : 36.90 Max. :20.000
## wd slp tot_cl
## Min. : 0.0 Min. : 0.08 Min. :0.000
## 1st Qu.:101.0 1st Qu.: 993.80 1st Qu.:3.000
## Median :200.0 Median :1000.70 Median :6.000
## Mean :190.3 Mean :1000.39 Mean :5.191
## 3rd Qu.:270.0 3rd Qu.:1007.20 3rd Qu.:7.000
## Max. :999.0 Max. :1038.90 Max. :9.0009.1 Wybór kolumn - select()
Niejednokrotnie wczytywane przez nas zbiory danych meteorologicznych zawierają znacznie więcej kolumn niż potrzebujemy. Jeśli chcemy wybrać lub pozbyć się niektórych kolumn najwygodniej użyć funkcji select().
Korzystanie z funkcji select() wymaga podania jako pierwszego argumentu nazwy zbioru, a następnie po przecinku (bez *" “*) należy podać nazwy kolumn (w dowolnej kolejności) które mają zostać wyświetlone.
Przykład: Jeśli chcemy wybrać jedynie wartości z nazwą stacji, rokiem, miesiącem, dniem, godziną, temperaturą powietrza oraz zachmurzeniem składnia takiego polecenia wyglądała by następująco:
library(dplyr) # nie zapomnijmy o aktywacji paczki dplyr po uruchomieniu RStudio!
test <- select(dane, nazwa, yy, mm, dd, hh, t2m, tot_cl)
head(test)## nazwa yy mm dd hh t2m tot_cl
## 1 POZ 2000 1 1 0 -1.1 8
## 2 POZ 2000 1 1 1 -1.1 8
## 3 POZ 2000 1 1 2 -1.1 8
## 4 POZ 2000 1 1 3 -1.2 8
## 5 POZ 2000 1 1 4 -1.2 8
## 6 POZ 2000 1 1 5 -1.0 8W powyższym przykładzie konieczne było podanie aż 7 z 11 nazw kolumn. W takim przypadku można wykorzystać opcję eliminacji wybranych kolumn poprzez zastosowanie znaku minusa ( - ) w odniesniu do kolumn których chcemy się pozbyć. Taki sam efekt jak we wcześniejszym przykładzie można uzyskać zatem poprzez:
Przykład:
test <- select(dane, -kod, -ws, -wd, -slp)
head(test)## nazwa yy mm dd hh t2m tot_cl
## 1 POZ 2000 1 1 0 -1.1 8
## 2 POZ 2000 1 1 1 -1.1 8
## 3 POZ 2000 1 1 2 -1.1 8
## 4 POZ 2000 1 1 3 -1.2 8
## 5 POZ 2000 1 1 4 -1.2 8
## 6 POZ 2000 1 1 5 -1.0 8Kolejne ciekawe zastosowane selecta polega na zastosowaniu jako operatora : (dwukropka), który wybierze wszystkie kolumny znajdujące się w zakresie od wskazanej do wskazanej nazwy. Wcześniejsze poleceni
Przykład:
test <- select(dane, nazwa:hh,t2m, tot_cl)
head(test)## nazwa yy mm dd hh t2m tot_cl
## 1 POZ 2000 1 1 0 -1.1 8
## 2 POZ 2000 1 1 1 -1.1 8
## 3 POZ 2000 1 1 2 -1.1 8
## 4 POZ 2000 1 1 3 -1.2 8
## 5 POZ 2000 1 1 4 -1.2 8
## 6 POZ 2000 1 1 5 -1.0 8Więcej praktycznych przykładów zastosowania pakietu dplyr można znaleźć w rzeczonym we wstępie do niniejszego rozdziału cheat-sheetcie w podrozdziale Helper functions for select… .
Zadanie:
- Wybierz ze zbioru
danetylko kolumny dla nazwy, kodu, roku, miesiąca oraz zredukowanego ciśnienia atmosferycznego i zapisz je do zbiorutest - Wybierz ze zbioru
danetylko kolumny z nazwami stacji oraz wszystkich parametrów meteorologicznych. Zastosuj zapis negacji (tj. z wykorzystaniem znaku minusa) dla usuwanych kolumn i zapisz wynik działania jakotest2
9.2 Filtrowanie
Duże zbiory danych meteorologicznych wymagają odfiltrowania (usunięcia/wybrania) części informacji zapisanych w wierszach. Odfiltrowywanie danych jest w wielu przypadkach wymagane np. w celu znalezienia i eliminacji błędów z bazy danych lub uzyskania kształtu ramki danych tylko dla interesujących nas przypadków.
Do wyświetlania/usuwania wybranych wierszy (oprócz poznanych wcześniej operatorów [] oraz operatorów zapytań logicznych) wygodne w użyciu może okazać się wykorzystanie funkcji filter().
Przykład 1 Baza dane zawiera wartości pomiarowe dla kilku stacji meteorologicznych. Informacje o tym jakie to są stacje można sprawdzić wyświetlając np. unikalne wartości kolumny kod lub nazwa.
unique(dane$nazwa) # wyświetla wartości unikalne z podanego wektora## [1] "POZ" "WAR" "LOD"Okazuje się, że w bazie są dane dla 3 stacji IMGW-PIB, które oznaczono w bazie 3 literowymi skrótami: Poznań (POZ), Warszawa (WAR) oraz ŁÓDŹ (LOD). Jeśli do naszej dalszej pracy potrzebna jest tylko 1 stacja (np. Poznań), wówczas możemy odfiltrować wiersze tylko do tych zawierających słowo “POZ” w kolumnie nazwa:
test <- filter(dane, nazwa=="POZ")
head(test)## kod nazwa yy mm dd hh t2m ws wd slp tot_cl
## 1 352160330 POZ 2000 1 1 0 -1.1 3 250 1014.2 8
## 2 352160330 POZ 2000 1 1 1 -1.1 2 280 1014.2 8
## 3 352160330 POZ 2000 1 1 2 -1.1 2 250 1014.3 8
## 4 352160330 POZ 2000 1 1 3 -1.2 2 240 1014.3 8
## 5 352160330 POZ 2000 1 1 4 -1.2 2 200 1014.3 8
## 6 352160330 POZ 2000 1 1 5 -1.0 1 170 1014.3 8Zwróć uwagę, że nazwę kolumny (nazwa) ponownie wpisaliśmy bez cudzysłowów, natomiast poszukiwana wartość (POZ) jest tekstem, więc tym razem konieczne było zastosowanie " ".
Przykład 2 Stosowane operatory logiczne dla funkcji filter() są tożsame z poznanymi we wcześniejszych częściach naszego kursu. Jeśli chcemy jednocześnie odfiltrować np. tylko wiersze, które zawierają w kolumnie nazwa wartości “POZ” i jednocześnie obejmują miesiące meteorologicznego lata (VI-VIII), to składnia takiego polecenia może być następująca:
test <- filter(dane, nazwa=="POZ", mm>=6 & mm<=8)
head(test)## kod nazwa yy mm dd hh t2m ws wd slp tot_cl
## 1 352160330 POZ 2000 6 1 0 4.6 1 280 1013.2 0
## 2 352160330 POZ 2000 6 1 1 4.6 0 0 1013.6 2
## 3 352160330 POZ 2000 6 1 2 3.3 0 0 1013.7 2
## 4 352160330 POZ 2000 6 1 3 3.5 1 360 1014.0 3
## 5 352160330 POZ 2000 6 1 4 6.2 1 90 1014.3 3
## 6 352160330 POZ 2000 6 1 5 9.7 2 100 1014.6 3Przykład 3 Powyższy przykład z wyborem więcej niż jednej pasującej wartości w danej kolumnie nie zawsze musi być tak trywialny aby dało się go rozpisać za pomocą pojedynczego wyrażenia logicznego. W takich przypadkach można zastosować odfiltrowywanie wierszy za pomocą porównania więcej niż jednego elementu, który musi zostać zadeklarowany jako wektor po operatorze %in% .
Jeśli interesują nas tylko wiersze obejmujące miesiące zimowe (XII-II) i tylko z Poznania (POZ) oraz Łodzi możemy spróbować działanie poniższej komendy:
test <- filter(dane, nazwa %in% c("POZ","LOD"), mm %in% c(12,1,2))
head(test)## kod nazwa yy mm dd hh t2m ws wd slp tot_cl
## 1 352160330 POZ 2000 1 1 0 -1.1 3 250 1014.2 8
## 2 352160330 POZ 2000 1 1 1 -1.1 2 280 1014.2 8
## 3 352160330 POZ 2000 1 1 2 -1.1 2 250 1014.3 8
## 4 352160330 POZ 2000 1 1 3 -1.2 2 240 1014.3 8
## 5 352160330 POZ 2000 1 1 4 -1.2 2 200 1014.3 8
## 6 352160330 POZ 2000 1 1 5 -1.0 1 170 1014.3 8unique(test$mm) # sprawdzmy czy na pewno sa tylko miesiace zimowe## [1] 1 2 12unique(test$nazwa) # sprawdzmy czy na pewno sa tylko wybrane stacje## [1] "POZ" "LOD"Przykład 4 Rozpoznanie błędów w bazach danych meteorologicznych nie należy do zadań łatwych. Część błędów można jednak dość łatwo rozpoznać znając fizyczne ograniczenia występujących wartości. Sprawdźmy naszą bazę pod tym kątem na przykładzie zachmurzenia ogólnego nieba, które jest podawane w oktantach (0-8). Jeśli chcemy sprawdzić czy istnieją wartości nie mieszczące się w tym zakresie możemy spróbować zdefiniować takie zapytanie logiczne, które umożliwi nam zweryfikowanie takich informacji i zapisanie ich do nowego obiektu:
bledy <- filter(dane, tot_cl<0 | tot_cl>8)
head(bledy)## kod nazwa yy mm dd hh t2m ws wd slp tot_cl
## 1 352160330 POZ 2000 3 23 5 -1.6 1 210 1004.5 9
## 2 352160330 POZ 2000 3 26 1 3.4 1 190 1003.1 9
## 3 352160330 POZ 2000 3 26 2 3.4 1 200 1002.9 9
## 4 352160330 POZ 2000 9 5 23 7.8 0 0 1008.6 9
## 5 352160330 POZ 2000 9 6 0 8.7 1 350 1008.6 9
## 6 352160330 POZ 2000 9 6 1 7.3 0 0 1008.6 9** Zadanie **
- Znajdź wiersze w których ciśnienie atmosferyczne zawiera błędne dane
- Odfiltruj bazę danych w taki sposób aby zawierały tylko dane dla Poznania i Warszawy. Wynik zapisz do nowego obiektu
test1 - Odfiltruj bazę danych
test1w taki sposób aby nowa bazatest2zawierała tylko dane dla Poznania, z miesięcy letnich po roku 2005 4a. Oblicz (a) średnią, (b) minimalną i (c) maksymalną temperaturę powietrza jaka wystąpiła w Poznaniu w tym czasie. 4b. Oblicz (a) średnią (b) oraz maksymalną prędkość wiatru
Podpowiedź: Szybkie filtrowanie danych jest dostępne również za pomocą graficznej przeglądarki RStudio po kliknięciu w ikonę Filter (ale bez możliwości zapisania wykonanego zapytania do pliku). W trybie graficznym możliwe jest także sortowanie wierszy po kliknięciu (jedno- lub dwukrotnym) w nazwę danej kolumny.
Ekran początkowy programu RStudio
9.3 Sortowanie - arrange
Sortowanie wierszy w R możliwe jest na co najmniej kilka sposobów. W pakiecie dplyr funkcja odpowiedzialna za sortowanie ramek danych to arrange(). Działa ona bardzo podobnie do select(), gdzie na pierwszym miejscu jako argument podaje się nazwę ramki danych, a w kolejnych nazwy kolumn.
Przykład 1 Wyświetlmy kilka najchłodniejszych pomiarów (kolumna t2m) z całej bazy (domyślnie sortowanie odbywa się od wartości najmniejszych do największych):
test <- arrange(dane, t2m)
head(test)## kod nazwa yy mm dd hh t2m ws wd slp tot_cl
## 1 351190465 LOD 2006 1 23 6 -30.1 0 0 1023.0 0
## 2 351190465 LOD 2006 1 23 3 -29.7 1 180 1022.0 0
## 3 351190465 LOD 2006 1 23 5 -29.7 0 0 1023.0 0
## 4 351190465 LOD 2006 1 23 2 -29.5 0 0 1022.0 0
## 5 351190465 LOD 2006 1 23 7 -29.5 0 0 1023.5 0
## 6 351190465 LOD 2006 1 22 23 -28.8 1 240 1021.0 0Przykład 2 Jeśli chcemy zmienić domyślną (narastającą) kolejność sortowania możemy odwrócić kierunek sortowania za pomocą znaku minusa przy nazwie kolumny. Sprawdźmy zatem kilka rekordowych wartości temperatur powietrza zanotowanych na analizowanych stacjach:
test <- arrange(dane, -t2m)
head(test)## kod nazwa yy mm dd hh t2m ws wd slp tot_cl
## 1 351190465 LOD 2013 8 8 14 36.9 6 204 989.8 2
## 2 352160330 POZ 2015 8 8 14 36.8 1 137 1004.9 1
## 3 352200375 WAR 2013 8 8 13 36.7 4 152 1000.0 2
## 4 352200375 WAR 2013 8 8 15 36.7 2 191 999.8 4
## 5 352200375 WAR 2013 8 8 14 36.6 2 185 1000.0 4
## 6 351190465 LOD 2013 8 8 13 36.5 7 208 989.8 4# okazuje sie, ze wszedzie najcieplejszy byl 8. sierpnia, choc...** Przykład 3 **
W przypadku w którym wartości sortowane mają takie same wartości często wykorzystywaną procedurą jest sortowanie po większej liczbie kolumn. Spróbujmy zatem ułożyć dane nie w kolejności dla stacji, ale po datach. Jako że wartości dla dat przechowywane są w 4 kolumnach (od “yy” do “hh”) ważne jest określenie odpowiedniej kolejności sortowania:
test <- arrange(dane, yy,mm,dd,hh,nazwa)
head(test)## kod nazwa yy mm dd hh t2m ws wd slp tot_cl
## 1 352160330 POZ 2000 1 1 0 -1.1 3 250 1014.2 8
## 2 351190465 LOD 2000 1 1 1 -1.8 2 270 1001.6 8
## 3 352160330 POZ 2000 1 1 1 -1.1 2 280 1014.2 8
## 4 352200375 WAR 2000 1 1 1 0.0 2 280 1011.2 8
## 5 351190465 LOD 2000 1 1 2 -1.7 1 250 1001.5 8
## 6 352160330 POZ 2000 1 1 2 -1.1 2 250 1014.3 8** Zadanie **
- Posortuj dane w kolejności od największych do najmniejszych prędkości wiatru. Zapisz wynik sortowania do obiektu
test - Korzystając z komendy
table()policz ile razy każda ze stacji pojawia się w zestawieniu 30-tu pomiarów z największymi prędkościami wiatru
9.4 Przetwarzanie potokowe
Pakiet dplyr zrewolucjonizował przetwarzanie danych w środowisku R na wiele sposobów. Jednym z nich jest zastosowanie przetwarzania potokowego (zwanego również przetwarzaniem sekwencyjnym), które nie tylko zwiększa czytelność tworzonego kodu, ale także pozwala na pominięcie kroków pośrednich, które normalnie zapychałyby środowisko obliczeniowe.
W przetwarzaniu potokowym cykl przetwarzania dzieli się na odrębne bloki, z których każdy jest połączony z następnym. Dane po przejściu przez jeden blok trafiają do następnego, aż osiągną ostatni blok.
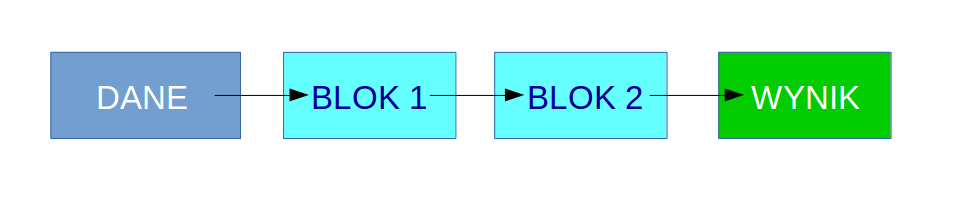
Schemat typowego przebiegu przetwarzania potokowego przy analizie danych
Operatorem przetwarzania potokowego w R jest %>% , który można wygenerować w RStudio za pomocą skrótu klawiszowego ctrl+shift+m. Operator %>% przekierowuje strumień informacji do kolejnej komendy R, która działając na tymczasowym obiekcie przekazuje jej wynik do kolejnego bloku obliczeń. Jeśli zaistnieje konieczność odwołania się do informacji zawartych w strumieniu danych można się do niego odwołać poprzez symbol . (kropki).

Przetwarzanie potokowego w R
Przykład 1 Na początek przypomnijmy sobie zawartość wbudowanego zbioru airquality
head(airquality)## Ozone Solar.R Wind Temp Month Day TempC
## 1 41 190 7.4 100 5 1 37.77778
## 2 36 118 8.0 72 5 2 22.22222
## 3 12 149 12.6 74 5 3 23.33333
## 4 18 313 11.5 62 5 4 16.66667
## 5 NA NA 14.3 56 5 5 13.33333
## 6 28 NA 14.9 66 5 6 18.88889Ten sam efekt możemy uzyskać stosując przetwarzanie potokowe, wiedząc, że każda funkcja(x) w postaci przetwarzania potokowego to x %>% funkcja(), zatem:
airquality %>% head() #lub: airquality %>% head(.)## Ozone Solar.R Wind Temp Month Day TempC
## 1 41 190 7.4 100 5 1 37.77778
## 2 36 118 8.0 72 5 2 22.22222
## 3 12 149 12.6 74 5 3 23.33333
## 4 18 313 11.5 62 5 4 16.66667
## 5 NA NA 14.3 56 5 5 13.33333
## 6 28 NA 14.9 66 5 6 18.88889Przykład 2 Jeśli chcemy wybrać jedynie dni, w których (1) temperatura powietrza przekroczyła 90F, (2) chcemy się pozbyć niechcianych kolumn pozostawiając jedynie kolumny Temp i Month i Day, (3) chcemy posortować te dni w kolejności od najcieplejszych do najchłodniejszych, to ten efekt przy klasycznym przetwarzaniu danych byłby rozpisany w kilku krokach:
krok1 <- filter(airquality, Temp>90) # wybieramy wiersza w których temperatura powietrza > 90
krok2 <- select(krok1, Temp:Day) # wybieramy tylko wskazane kolumny
krok3 <- arrange(krok2, -Temp) # sortujemy od najwyższych do najniższych temperaturTeoretycznie ten sam efekt można uzyskać w jednym kroku, stosując np. tzw. zapis na cebulkę, choć jego czytelność pozostawia wiele do życzenia:
arrange(
select(
filter(airquality, Temp>90), # pierwsza funkcja
Temp:Day), # dokończenie funkcji select
-Temp) # dokończenie funkcji arrange## Temp Month Day
## 1 100 5 1
## 2 97 8 28
## 3 96 8 30
## 4 94 8 29
## 5 94 8 31
## 6 93 6 11
## 7 93 9 3
## 8 93 9 4
## 9 92 6 12
## 10 92 7 8
## 11 92 7 9
## 12 92 8 10
## 13 92 9 2
## 14 91 7 14
## 15 91 9 1Przy zastosowaniu przetwarzania potokowego:
airquality %>% filter(Temp>90) %>% select(Temp:Day) %>% arrange(-Temp)## Temp Month Day
## 1 100 5 1
## 2 97 8 28
## 3 96 8 30
## 4 94 8 29
## 5 94 8 31
## 6 93 6 11
## 7 93 9 3
## 8 93 9 4
## 9 92 6 12
## 10 92 7 8
## 11 92 7 9
## 12 92 8 10
## 13 92 9 2
## 14 91 7 14
## 15 91 9 1# lub w wersji z kropką: airquality %>% filter(., Temp>90) %>% select(., Temp:Day) %>% arrange(., -Temp)Zadanie:
- Pobierz ponownie dane z pliku http://enwo.pl/przetwarzanie/dane/synop.rds i zapisz jako obiekt
dane(możesz także wykorzystać gotowy kod:dane <- readRDS(gzcon(url("http://enwo.pl/przetwarzanie/dane/synop.rds")))) - Korzystając z przetwarzania potokowego wybierz jedynie dane meteorologiczne dla Poznania
- W kolejnym bloku kodu wybierz jedynie miesiące letnie (VI-VIII)
- W kolejnym bloku kodu uszereguj wyniki od najniższych temperatur jakie odnotowano latem
- Zapisz rezultat działania do nowego obiektu, który nazwiesz
wynik
9.5 group_by() oraz summarise()
Z punktu widzenia przetwarzania danych w naukach atmosferycznych niezwykle ważna jest możliwość szybkiego tworzenia tzw. agregatów, czyli tworzenia podsumowań dla analizowanych zbiorów danych. Do tego celu niezwykle przydatne są 2 funkcje z pakietu dplyr: group_by() oraz summarise().
Jak sama nazwa wskazuje funkcja group_by() grupuje zbiory danych po unikalnych wartościach we wskazanych kolumnach ramki danych. Przykładowo, jeśli wskażemy do grupowania kolumny yy, mm, dd, wówczas będą one grupowały poszczególne wiersze w ramce danych jak na wskazanym poniżej przykładzie:
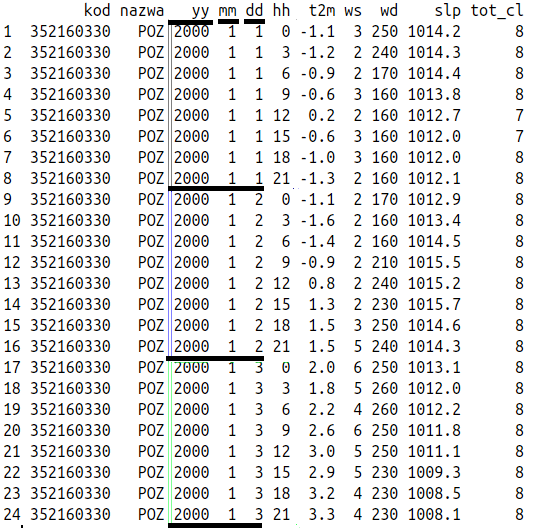
Zasięg oddziaływania funkcji group_by() przy wskazaniu jako grupujących kolumn yy, mm, dd
Samo grupowanie nie daje widocznych efektów. Jego wynik może być jednak z powodzeniem wykorzystany przez funkcję summarise(), która pozwala na wykonanie dowolnej funkcji w obrębie wydzielonych zagregowań. Takie postępowanie można z powodzeniem wykorzystać do obliczenia podstawowych statystyk meteorologicznych/klimatologicznych.
Przykład 1 Poniższy fragment kodu grupujący po kolumnie yy (lata) pozwoli na zgrupowanie wszystkich wierszy, które zawierają takie same wartości w tej kolumnie (tu: rok). Następnie dane są przekazywane do do funkcji summarise(), w której obliczamy średnie z kolumny z wartościami temperatury:
dane %>% group_by(yy) %>% summarise( mean(t2m) )## # A tibble: 16 x 2
## yy `mean(t2m)`
## <int> <dbl>
## 1 2000 9.76
## 2 2001 8.47
## 3 2002 9.38
## 4 2003 8.61
## 5 2004 8.66
## 6 2005 8.80
## 7 2006 9.20
## 8 2007 9.71
## 9 2008 9.85
## 10 2009 8.92
## 11 2010 7.77
## 12 2011 9.30
## 13 2012 8.96
## 14 2013 8.87
## 15 2014 10.1
## 16 2015 10.2Czy uzyskany zbiór danych zawiera informacje dla temperatury średniej rocznej w Poznaniu? Nie! W ramce danych mamy pomiary z kilku stacji meteorologicznych. Z tego względu bez względu czy pomiar był w Poznaniu czy Łodzi, czy w Warszawie wszystkie pomiary z danego roku zostały wrzucone do tej samej grupy (agregaty). W takim przypadku konieczne jest albo wcześniejsze odfiltrowania zbioru danych, albo rozszerzenie argumentów funkcji group_by(), tak aby wykonała obliczenia dla większej liczby stacji, np.:
dane %>% group_by(nazwa, yy) %>% summarise( mean(t2m) )## # A tibble: 48 x 3
## # Groups: nazwa [?]
## nazwa yy `mean(t2m)`
## <chr> <int> <dbl>
## 1 LOD 2000 9.60
## 2 LOD 2001 8.13
## 3 LOD 2002 9.10
## 4 LOD 2003 8.53
## 5 LOD 2004 8.53
## 6 LOD 2005 8.64
## 7 LOD 2006 8.87
## 8 LOD 2007 9.35
## 9 LOD 2008 9.58
## 10 LOD 2009 8.63
## # ... with 38 more rowsZadanie:
- Oblicz średnie miesięczne temperatury powietrza w wieloleciu 2000-2015 w Poznaniu (czyli np. I:-0.2*C, II:-2.1, III:+2.6, itd.)
- Oblicz maksymalne temperatury jakie wystąpiły w każdym z miesięcy w wieloleciu 2000-2015 w Poznaniu (czyli np. 2000-I: +2.8*C, 2000-II:+6.1, 2000-III:+12.6, itd.)
- Oblicz sumę temperatur w każdym dniu kalendarzowym w Poznaniu (analogiczną procedurę można by było zastosować np. do opadów atmosferycznych)
Wskazówka: Nazwy kolumn w funkcji summarise() można dowolnie definiować. Przykładowo, jeśli chcielibyśmy obliczyć jednocześnie temperaturę maksymalną i minimalną dobową w Poznaniu latem 2015 r., wówczas kolumny wynikowe możemy odpowiednio nazwać: `
dane %>% filter(., nazwa=="POZ", yy==2015, mm %in% c(6:8)) %>% group_by(yy,mm,dd) %>% summarise( temp_min=min(t2m, na.rm=T) , temp_max=max(t2m, na.rm=T) )## # A tibble: 92 x 5
## # Groups: yy, mm [?]
## yy mm dd temp_min temp_max
## <int> <int> <int> <dbl> <dbl>
## 1 2015 6 1 12.5 22.6
## 2 2015 6 2 10.7 24.9
## 3 2015 6 3 12.1 28.4
## 4 2015 6 4 9.2 21.7
## 5 2015 6 5 9.7 26.1
## 6 2015 6 6 15.2 31.6
## 7 2015 6 7 11.8 18.2
## 8 2015 6 8 9.2 20.5
## 9 2015 6 9 8.2 14.8
## 10 2015 6 10 8.6 20.7
## # ... with 82 more rows